ЧАСТЬ IV МОДЕЛИ РЕЧЕВОЙ ДЕЯТЕЛЬНОСТИ
Данная часть посвящена основному типу лингвистических моделей — моделям речевой деятельности человека. Достигнутый в этой области прогресс весьма значителен. Разработаны первые варианты моделей фонологического анализа и синтеза , , , разлагающие звуковой поток в фонологические признаки и синтезирующие важные компоненты речи, включая ее интонационные характеристики .
Для многих языков построены алгоритмы автоматического морфологического анализа , , , которые каждую словоформу разлагают на ее основу и информацию о выражаемых словоформой грамматических значениях (например, значениях падежа, числа и т. п. для существительных, значениях лица, времени, наклонения и т^ п. для глаголов и т. д.). Имеются алгоритмы автоматического ^сйнтеза, которые конструируют некоторую словоформу по ее основе и набору информаций о грамматических значениях этой словоформы , , . Наиболее систематическим изложением морфологии с указанной здесь синтетической точки зрения, восходящей к упоминавшимся в I части работам Ф. Брюно и О. Есперсена, является докторская-диссертация А. А. Зализняка «Классификация и синтез именных парадигм современного русского языка» [56]. Существует большое число синтаксических алгоритмов анализа и синтеза текстов А + В, или S C+D и т. д.Чтобы иллюстрировать эти принципы, рассмотрим пример порождения предложений по правилам следующей простой грамматики: 1) N ->■ man — «мужчина», boy — «мальчик»; 2) S NP+VP; 3) V heard — «слышал»; saw — «видел»; 4) NP T+N; 5) Т ->■ the (определенный артикль); 6) VP V+N. В начале порождающего процесса символ S засылается в решающее устройство/Решаю- щее устройство делает две вещи: во-первых, оно подает поступивший в него символ в устройство вывода для печати; во-вторых, оно обращается к грамматике, хранящейся в постоянной памяти, чтобы развернуть символ по какому-либо из ее правил.
Применено может быть любое правило, левый символ которого, стоящий до стрелки, совпадает с символом, находящимся в данный момент в решающем устройстве. В нашем случае таким правилом является S -> NP+VP. Каждый раз, когда применено какое-то грамматическое правило, крайняя левая непосредственно составляющая полученной в результате конструкции (в нашем случае — составляющая NP конструкции NP+VP) направляется в решающее устройство, а все стоящие справа от него символы (в нашем случае — VP) —- в быстродействующую память, где они ждут своей очереди на развертывание. Если находящийся в решающем устройстве символ не является терминальным (см. определение на стр. 199), то решающее устройство обрабатывает его по тем же правилам, что и символ 5, т. е. подает его в устройство вывода для печати и обращается к грамматичес- ким правилам, чтобы заменить его новым символом или символами. Если же символ является терминальным, то решающее устройство подает его на выход, обращается к быстродействующей памяти, хранящей промежуточные результаты, и обрабатывает по тем же правилам первый стоящий на очереди символ. Если в быстродействующей памяти никаких промежуточных символов больше нет, то решающее устройство подает на выход точечный знак (конец предложения).Изложенный алгоритм порождает по правилам нашей грамматики, в частности, следующее предложение: The man saw the boy — «Мужчина увидел мальчика». Процесс порождения этого предложения может быть представлен следующей схемой (см. схему 3).
Добавление к этой простой грамматике некоторых рекурсивных правил позволяет порождать предложения сколь угодно большой длины, т. е. бесконечное множество предложений. Среди этих правил имеются три правила порождения предложений с однородными членами, одно правило порождения предложений с последовательным подчинением и одно правило порождения сложных предложений (с рекурсивным элементом S).
Все порождаемые предложения обязаны быть «грамматически правильными», но не обязаны быть осмысленными.
Приведем образцы порождаемых машиной предложений (основой для них послужили грамматика и словарь, содержавшиеся в десяти предложениях книжки для детей, за тем исключением, что грамматические правила были расширены указанным выше образом):1. Не has four polished sand-domes — «У него (человека) есть четыре блестящих песчаных купола».
2. Не has four proud, little, polished, polished and proud boilers under proud bells, steam and whistles in four whistles — «У него есть четыре гордых, маленьких, отполированных, отполированных и гордых котла под гордыми звоночками, пар и свистки в четырех свистках».
3. The steam makes its steam and a whistle big and proud — «Пар делает свой пар и свисток большими и гордыми».
4. When engineer Small is oiled, the water in the bells is heated — «Когда инженер Смол смазан, вода в звонках подогревается».
| Выход | Решающее устройство | Быстро действующая память |
| S | ||
| 5 | NP | VP |
| SNP | T | N VP |
| S NP T | the | N VP |
| S NP T the | N | VP |
| S NP T the N | man | VP |
| S NP T the N man | VP | |
| S NP T the N man VP | V | NP |
| S NP T the N man VP V | saw | NP |
| S NP T the N man VP V saw | NP | |
| S NP T the N man VP V saw NP | T | N |
| S NP T the N man VP V saw NP T | the | N |
| S NP T the N man VP V saw NP T the | N | |
| S NP T the N man VP V saw NP T the N | boy | |
| S NP T the N man VP V saw NP T the N boy |
5.
Engineer Small is polished — «Инженер Смол отполирован».6. A fire-box is proud of Small — «Топка гордится Смолом».
В других экспериментах порождались предложения и более сложной синтаксической структуры :
1. After he is covered, it never admires his steam — «После того как он покрыт, оно никогда не восхищается его паром».
2. In what way isn't a rug old, and why is he wiry and cool — «В каком смысле коврик не является старым и почему он жилист и хладнокровен».
3. She makes six boilers and six tragic and new legs — «Она делает шесть котлов и шесть трагических и новых ног».
4. What is he cooled for — «Зачем он охлаждается»?
5. It по longer runs it, nor does she put it under four smooth floors — «Оно больше им не управляет, и не кладет она его под четыре гладких пола».
6. Isn’t she polished under Miss Macpherson and plants — t «Ну не отполирована ли она под Мисс Макферсон и растениями».
Как видим, машина довольно успешно учится говорить на человеческом языке, и свои первые шаги на этом новом и трудном для нее поприще она делает в некоторых отно-‘ шениях гораздо уверенней, чем ребенок, осваивающий свой родной язык, или взрослый, изучающий иностранный язык. Заметим, что для порождения приведенных выше предложений машине потребовалось знание весьма тонких грамматических механизмов.
По мнению В. Ингве, программа, использованная для порождения этих предложений, не обнаружила никаких существенных недостатков. «До сих пор не было причин сомневаться в том, что можно будет использовать ту же самую формальную систему в полной грамматике английского языка» .
Аналогичные принципы положены в основу грамматик НС французского, арабского, русского и других языков, разрабатываемых группой В. Ингве в США и его последователями в других странах. Ниже мы остановимся только на одной из таких грамматик. Это — грамматика порождения по НС для русского языка, предложенная Н. Г. Арсентьевой и представляющая собой в некоторых отношениях существенный шаг вперед , .
Отличие модели Н. Г. Арсентьевой от рассмотренной выше модели В. Ингве состоит в том, что заложенный в модель словарь разбит на семантические классы (два класса — переходных и непереходных — глаголов, причем для каждого глагола указан тип управления, 33 класса существительных, 29 классов прилагательных, 7 классов наречий и т. д.). Для каждого конкретного глагола указывается, из каких классов существительных он может принимать подлежащее и дополнения, а также из каких .классов наречий — обстоятельства. Для каждого существительного указаны аналогичным образом классы прилагательных и причастий и т. п. Это обеспечивает порождение по более или менее обычным правилам развертывания по НС частично осмысленных предложений; именно, в порождаемых предложениях имеется осмысленность внутри элементарной синтагмы, хотя осмысленной связи между синтагмами еще нет.
Правила грамматики (свыше 200) и словарь, заложенные в машину, были получены в результате произведенного человеком анализа 50 предложений из «Повестей Белкина»; каждому правилу была приписана, в результате того же анализа, некоторая вероятность выбора (об этом понятии см. стр. 117). Модель была запрограммирована; машинные эксперименты дали следующие результаты (приводятся образцы порожденных предложений, общее число которых очень велико):
1. Вы будете беспокоить ваших стариков.
2. В самом деле я не ошибаюсь.
3. В трех верстах от лесов ваших вы ожидаете лошадь вашу долго.
4. Вы наедине делали весь ром, находившийся за переписками стройных красавиц в трех верстах от богатых и счастливых домиков.
5. Мы, заметя старого или решительного сына, найдем лошадь твоих прапорщиков.
6. Ты в год для твоих картинок или романов для особы, матю, находившейся под мешком жителя, достопамятным вашей жене, на красных деньгах лошадей наших стройных молодцов избранной, будешь пылать под пистолетами или пистолетом, стройными, стройными невестами избранными.
Для сравнения приведем образцы предложений, порожденных первыми вариантами модели, в которых словарь не был разбит на семантические классы.
1. Разумеется, что бедным или нечаянным молодцам подадут уединение.
2. Накануне следующей склонности уездного мешка милый сосед, крестный жаркий день накануне мучительного или мучительного уединения.
3. Будут прочить объяснения своих за жителя нашего сосновые воображения.
4. Отставная отставная станция, красота постарше, чем ты, будет думать о воскресном нечаянном чтении в трех верстах от крестных армейских голосов.
5. Накануне отставного богатого объяснения мы жили, когда я поспешу, может быть, до меня.
6. Клянешься нам в свиданиях на пронзительных или тех же воображениях ты.
Чтобы оценить степень адекватности рассматриваемых здесь порождающих грамматик структуре естественных языков, проанализируем их более внимательно. Представим процесс порождения предложения The man saw the boy в виде дерева и пронумеруем все имеющиеся в нем узлы, включая терминальные, в порядке их развертывания:
__________________ Si________________
| np2 | VP, | ||||
| Та | Vs | NP10 | |||
| Ти | |||||
The4 mariQ saw9 the12 boyu
Легко заметить, что машина сначала обрабатывает крайнюю левую ветвь дерева; дойдя до конца этой ветви (точки The^y она возвращается к ближайшему узлу, в котором началось ветвление влево (NP2), и заканчивает крайний левый куст дерева. Затем она возвращается к следующему узлу дерева (Sx) и снова обрабатывает левую ветвь очередного куста и т. д. Поскольку любая левая ветвь заставляет машину возвращаться к некоторой исходной точке, ветвящиеся влево структуры называются регрессивными. Ветвящиеся вправо структуры, не обладающие этим свойством, называются соответственно прогрессивными.
Когда машина обрабатывает регрессивную структуру, она должна хранить в быстродействующей памяти все промежуточные результаты (символы), причем чем дальше влево ветвится структура, тем больше число символов, которые необходимо запомнить. Для дерева, изображенного на рисунке 10, I, машина должна хранить в памяти максимум два символа, а для дерева, изображенного на рисунке 10, II, число таких символов равно трем.
/
о
0
О І
| 1 О» | |
| (2) С | ) (1) |
0 і
О) (0)
(0) (3) Рис. 10.
Последнее дерево соответствует, например, предложению Хорошо переведенный текст читается легко. Первым действует правило S -> NP+VP; VP направляется в быстродействующую память, a NP развертывается по правилу NP -* A+N; N в свою очередь направляется в быстродействующую память, а А развертывается по правилу А -* D+A; наконец, А отправляется в быстродействующую память, которая теперь содержит три символа (VP, N и A), a D заменяется символом хорошо.
Максимальное число символов, которое машина должна хранить в быстродействующей памяти при порождении некоторого предложения, называется глубиной данного предложения. Глубина максимально глубокого предложения называется глубиной данного языка. Глубину предложения можно подсчитать, пронумеровав ветви справа налево в точках ветвления, как показано на рисунке 10, и сложив единички, встречающиеся на пути к терминальной точке (см. цифры в круглых скобках). Легко заметить, что глубина предложений и, следовательно, языков растет исключительно за счет регрессивных структур, так как при развертывании прогрессивных структур машина не должна запоминать значительных по количеству промежуточных результатов.
Из сказанного следует, что модель В. Ингве может порождать предложения с прогрессивными структурами сколь угодно большой длины. Она, однако, не может порождать предложений с бесконечно растущими регрессивными структурами, так как это потребовало бы быстродействующей памяти неограниченного (бесконечного) объема, а у всякой практически реализуемой машины объем памяти обязан быть конечным. Таким образом, глубина порождаемых машиной предложений ограничена максимальным объемом ее быстродействующей памяти.
После этих предварительных замечаний мы можем перейти к наиболее интересным идеям, связанным с моделью порождения по НС.
Каждая грамматическая модель неизбежно является некоторой гипотезой о том, как устроен в действительности механизм, работу которого она имитирует. Если подходить к лингвистическим моделям с этой точки зрения, то каждому механизму модели следует поставить в соответствие некий психический или физиологический механизм. При этом следует помнить, что механизмы модели всегда проще, чем соответствующие им механизмы мозга, и являются в лучшем случае аппроксимацией последних (см. стр. 81).
Порождающий механизм рассмотренной выше модели В. Ингве состоит, как мы помним, из четырех частей. Постоянной памяти естественно поставить в .соответствие память, а устройству вывода — речевые органы. Если мы хотим быть последовательными, мы должны предположить существование в мозге человека и других двух механизмов, соответствующих быстродействующей памяти и решающему устройству. Оказывается, что в пользу этого предположения можно привести весьма любопытные факты и соображения.
Психологическими экспериментами установлено, что человек в процессе обработки информации может одновременно хранить в памяти ограниченное число единиц, а именно 7±2 случайных чисел, не связанных друг с другом слов и т. п. . Этим объясняется, в частности, тот факт, что ему трудно производить и понимать предложения с большой глубиной типа If what going to a clearly not very adequately staffed school really means is little appreciated we should be concerned — «Если (в обществе) плохо понимают, что в действительности значит ходить в школу, штат которой явным образом не очень хорошо укомплектован, это должно нас озаботить» (глубина предложения равна 8). Здесь человек действует на пределе своих возможностей, так как заполнение его быстродействующей памяти близко к критической отметке (точке 9). Рассмотрим еще следующий пример: (1) Она знала человека, который сделал сообщение, которое удостоилось премии, которая была назначена за лучшую работу (ср. учитель-* учительствует), R2R3V (зреет-*зрелый-* -* зрелость, переводит -* переводимый -* переводимо с ть), R^R3V (зреет -* зрелый -* зрело, запаздывает -* -*запоздалый-*'Запоздало)пт. д. Можно сформулировать одно рекурсивное правило порождения производных основ:
1) N, V, A, D суть основы; 2) если X — основа, то и RmX (где m = 1, 2, 3 или 4) также основа .
До тех пор пока у нас не было правил порождения производных основ и пока каждое правило аппликации могло применяться, по условию, только однажды, модель была ограничена в своих возможностях: она не порождала ни одного действительно интересного комплекса (ср. примеры на стр. 225). Теперь же мы располагаем необходимыми средствами для того, чтобы снять эти ограничения и построить аналог практически любого типа слова, словосочетания и предложения. Эта задача сводится к тому, чтобы указать правила осложнения комплексов.
Элементарные комплексы могут быть осложнены несколькими способами. Во-первых, каждый из 14 элементарных комплексов мы можем превратить в неэлементарный, заменяя те или иные непроизводные основы производными, например R2XRxXRkX (ср. Сторож охраняет магазин), R2XRxXRJR2X (ср.г Старуха позеленела от злости) и т. п. Во-вторых, каждое правило аппликации можно применить не один раз, как это было сделано при порождении 14 элементарных комплексов, а п раз, причем п заранее никак не фиксировано, например R3XR3XR2X (ср. шерстяной пиджак в клетку), /?2Х/?1Х/?4Х/?4Х/?4Х (ср. Он вменяет мне в вину опоздание; Он внезапно распахнул дверь настежь) и т. п. В-третьих, неэлементарные комплексы можно получать по следующему рекурсивному определению: 1) элементарные комплексы (14 выражений) суть комплексы; 2) если X — комплекс, то и RmX — также комплекс. Из этого определения следует, что релятор может относиться не только к одной основе, но и к ряду основ, связанных отношением подчинения; иными словами, функцию того или иного класса может выполнять не только основа слова, но и «основа» словосочетания и предложения. Таким образом, это правило позволяет нам строить аналоги любых типов так называемых простых распространенных предложений, сложных предложений различных типов и т. п.; ср. комплекс R^R^R^ (R^XR^XR2X), соответствующий предложениям тйпа Сторожка стоит в очень глухом лесу, комплекс R2XRxXR^ (R2XRxXRkX), соответствующий предложению Он сказал, что поезд приходит ночью, и т. п.
Убедившись, что изложенные выше правила образования обеспечивают порождение, на идеальном уровне, достаточно разнообразных аналогов слов, словосочетаний и предложений, мы перейдем ко второму компоненту аппликативной порождающей модели, который содержит, как сказано выше, трансформационные правила преобразования комплексов. В модели С. К. Шаумяна, в отличие, например, от модели Н. Хомского, эти правила не задаются извне, а вырабатываются на основе имеющейся информации. Средством для выработки этих правил служит специальное исчисление трансформаций.
Трансформации делятся на связанные и несвязанные. Считается, что комплекс А' образован из комплекса А связанной трансформацией, если: 1) для любой основы Х(9 входящей в Л, в А' найдется основа Ху, образованная из Х( по правилам порождения производных основ (см. таблицу на стр. 227), и наоборот, для каждой основы Ху, входящей в А', в А найдется основа Xi9 от которой образована X/, 2) для любой пары основ Xt и Yі, входящих в Л и связанных отношением подчинения, в Л' найдется пара соответствующих основ Х\ и Y\, также связанных отношением подчинения, и наоборот (ср. определение трансформации на стр. 155). Примеры связанных трансформаций: R3XR2X-* R2R3XR3R2X (высокая гора -* высота горы); R2XRxX -* R3RxXR2X (поезд идет-* -* идущий поезд); R2XRxXR^X -* R2RxXR3R^XR3R2X (мальчик читает книгу -* чтение книги мальчиком). Преобразование называется несвязанным, если выполнено только первое из двух сформулированных выше условий.
Пример:
Звезды светят ночью
— усветлая звездная ночь —►звездные свет и ночь |-+ночные свет и звезды I -^светлая звезда в ночи —>ночь под светлой звездой —>■звезда в светлой ночи [66]
Чтобы показать, каким образом находятся все возможные трансформы данного комплекса, рассмотрим следующий пример. Возьмем трехчленный комплекс R2XRxXRkX (ср. Писатель завершает книгу), выпишем в столбик для каждой из входящих в него основ все основы следующей степени производности (для удобства повторив внизу первую строчку) и соединим пары основ в соседних столбиках таким образом, чтобы в результате получались парные комплексы, члены которых могут быть связаны отношением подчинения:
R2X RjX R4X
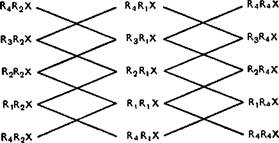
Переходя от каждого из элементов левого столбца к какому-нибудь элементу правого по одному из возможных путей, мы получим все трансформы исходного комплекса R^XR^XRilX первой степени производности. Всего, как легко подсчитать, он имеет 14 трансформов. Разумеется,
не все они получают интерпретацию в русском языке; к числу интерпретируемых трансформов относятся
R2R2XRsRxXRAR4X
R^R2XR3RiXR2R^X
R2RaXR1R1XR4R2X
R3R2XR2RxXR3R4X
Писатель, завершающий книгу Книга, завершенная писателем Книга завершается писателем
Завершение книги писателем и т. д.
Ключевыми в этой системе являются трансформации бинарных комплексов, называемые элементарными. Оказывается, что если у нас есть трансформации для каждого из четырех бинарных (двучленных) комплексов, то трансформации многочленных комплексов мы можем определить через эти элементарные трансформации. Действительно, приведенный выше трехчленный трансформ является (теоретико-множественным) объединением двух бинарных трансформов R2R2XR3RxX (J U R3RxXRkRkX\ аналогичным образом
R^R2XR3RxX U RsRiXR2RaX = Я4Я 2*Я зЯ 2Я Л
R^XR^X U R^XRtRtX = R^XR^XR^X
и т. д. Отсюда следует тот важный вывод, что для получения любой трансформации любого комплекса достаточно построить исчислениетрансформаций для бинарных комплексов.
R.x
Если обозначить надстрочным символом п степень производности некоторой основы и записать произвольный двучленный комплекс как RjXRkX, то в с е трансформы этого комплекса можно представить в обобщенном виде следующим образом:
RkX
Это и дает нам то абстрактное исчисление трансформаций, которое в дальнейшем направляет наши поиски конкретных интерпретируемых трансформаций. Приведем несколько примеров для бинарного комплекса RgAR^:
1. RsARtN-^-RiRaARaRtN
а) высокая гора —► высокогорный широкие плечи —► широкоплечий
б) глубокое несчастье —► глубоко несчастный
2. R3AR2NR3R3AR4R2N
а) широкие плечи —► широкий в плечах
б) слабое здоровье —► слабый здоровьем
3. R3AR2N—R2R3AR3R2N
а) высокая гора —► высота горы
б) высокая гора —► горная высота
4. R3AR2N-^ R2R3ARxR2N
высокая гора —► высота была горою
5. R3AR2N —► R1R3AR2R2N
высокая гора —► гора высится
6. R3AR2N^RXR3AR4R2N
широкие плечи—► (был) широк в плечах
7. R3AR2N—> R4R3ARxR2N
хороший обед —► хорошо пообедал
На этом мы заканчиваем изложение формального аппарата модели. Что касается правил интерпретации, то, насколько это допускал жанр нашей книги, они давались по ходу изложения формального аппарата модели, и поэтому мы не будем останавливаться на них особо.
Глава 2
СИНТАКСИЧЕСКИЕ МОДЕЛИ АНАЛИЗА
Переходя к рассмотрению моделей анализа, мы, по крайней мере частично, вступаем в область прикладной лингвистики, которая смежна со структурной лингвистикой, но не тождественна ей. Это — достаточно самостоятельная, широкая и перспективная область машинного перевода, автоматического реферирования текстов и других прикладных задач, .плодотворно разрабатываемая не только отдельными исследователями, но и
большими коллективами ученых, см. , ,
, , , , ,
, , , , , , , , , , , , , . Естественно, что в нашем кратком очерке мы не ставили и не могли ставить перед собой задачи нарисовать сколько-нибудь подробную ее картину, тем более что относящиеся к делу исследования в большинстве случаев насыщены техническими деталями, не представляющими интереса с точки зрения занимающей нас темы. Поскольку, однако, большинство непримитивных моделей анализа основаны на весьма интересных лингвистических предпосылках и являются к тому же действующими моделями речевой деятельности человека, они имеют теоретический интерес и должны быть, хотя бы кратко, представлены в нашей книге[67]. В дальнейшем мы даем суммарный очерк наиболее интересных подходов к решению общих лингвистических вопросов, возникающих в моделях такого рода. Две модели, одна из которых принадлежит И. А. Мельчуку, а другая И. Лесерфу, рассматриваются более подробно, чем остальные.
Как мы помним (см. стр. 108), задачу моделирования речевой деятельности человека в самом общем виде можно сформулировать следующим образом.Нам известны грамматика и словарь данного языка. Требуется построить алгоритмы «пользования» грамматикой и словарем, достаточные для того, чтобы машина могла «понять» всякое введенное в нее правильное предложение (в идеале — его смысл, для начала — хотя бы его синтаксическую структуру) и построить правильное предложение по введенной в нее смысловой или синтаксической информации. В данной главе мы будем рассматривать только синтаксические модели указанного здесь типа; мы ограничим себя еще и в том отношении, что оставим в стороне модели синтеза, которые основаны практически на том же круге идей, что и модели анализа, но разработаны гораздо менее детально.
Существуют четыре основных подхода к решению сформулированной выше задачи автоматического анализа текста (перехода от текста к содержащейся в нем синтаксической информации): последовательный анализ, п р е д с к а з у е м о с т и ы й анализ, поиск опорных точек и метод фильтров. Некоторые из них довольно близки друг другу и базируются на идеях, с которыми мы в той или иной мере уже знакомы.
ПОСЛЕДОВАТЕЛЬНЫЙ АНАЛИЗ
Рассмотрим следующее предложение из перевода романа Мельвиля «Моби Дик»: «Акт уплаты представляет собой, я полагаю, наиболее неприятную кару из тех, что навлекли на нас двое обирателей яблоневых садов». Каждый, кто владеет русским языком, поймет по крайней мере прямой смысл этого предложения. Однако его скрытый, аллегорический смысл будет доступен лишь тому, в чьей памяти хранится библейская легенда об Адаме и Еве и древе познания добра и зла, с которого Ева сорвала запретный плод и тем самым навлекла на человечество всяческие бедствия. Тот, кто не знает этой легенды, не поймет более глубокого и в данном контексте единственно важного смысла предложения. Аналогичным образом возникает непонимание и на других уровнях. Очень часто его причиной является то обстоятельство, что мы незнаем слова или (например, при разговоре на иностранном языке) грамматического оборота, употребленного нашим собеседником: в нашей памяти не хранится образца («эталона»), с которым можно было бы сравнить и отождествить поступившее в «устройство понимания» слово (или оборот).
Эти примеры показывают, что в некотором, достаточно узком, но интересном для нас смысле процесс понимания (анализа) текста можно представить как процедуру с о- поставления поступающей информации с информацией, хранящейся в памяти, и отождествления совпадающих частей информации.
В сущности, эта идея сопоставления поступающих в устройство понимания единице образцами, хранящимися в его памяти, и легла в основу методики последовательного автоматического анализа текста, основные принципы которой были сформулированы в 1954 году В. Ингве , . По мысли В. Ингве, анализирующее устройство, т. е. электронная вычислительная машина, должно хранить в памяти список (словарь) типичных для данного языка синтагм, записанных в виде последовательностей классов слов. Синтагмы рассматриваются в качестве своего рода эталонов; синтаксическая структура некоторого предложения отыскивается машиной в результате последовательного сопоставления различных цепочек словоформ данного предложения с эталонами, хранящимися в словаре, причем в качестве термина для сравнения каждый раз выбирается максимально длинная синтагма, целиком вкладывающаяся в анализируемое предложение. Найденным словосочетаниям приписываются номера соответствующих синтагм. После обнаружения всех словосочетаний данного предложения устанавливаются отношения между ними (иерархия словосочетаний), и синтаксический анализ предложения считается исчерпанным .
Предложенная В. Ингве методика отличается двумя главными достоинствами: «1. Синтаксический анализ сводится к небольшому числу однообразных, логически очень простых операций, которые осуществляют отыскание в тексте последовательностей из словаря. 2. Правила синтаксического анализа — одни и те же для любого языка. От языка к языку меняются лишь перечни типовых словосочетаний, а правила отыскания словосочетаний с помощью этих перечней остаются одинаковыми»
Еще по теме ЧАСТЬ IV МОДЕЛИ РЕЧЕВОЙ ДЕЯТЕЛЬНОСТИ:
- 30. Виды речевой деятельности. Речевые функции. Периферические и центральные механизмы речи.
- 56. Речевая деятельность
- 6. Под речевой деятельностью следует
- II. 8.2. Физиологические механизмы речевой деятельности
- II. 8. 3. Виды речевой деятельности
- Виды речевой деятельности
- 10.1. Понятие о речевой деятельности.
- Виды и формы речевой деятельности. Понятие об афазиях.
- 34. Роль правого полушария в организации речевой деятельности.
- Психология речевой деятельности.
- II. 8. 1. Язык, общение, речевая деятельность
- 11. Виды речевой деятельности и их особенности
- Часть I. Правовые нормы, регулирующие деятельность административных ведомств и предписывающие порядок этой деятельности
- 25 Речевые нарушения, связанные с поражением эфферентных звеньев речевой функциональной системы
- Тест 24. Речевое взаимодействие. Основные единицы общения. Логические основы речевого общения
- Речевой этикет. Русский речевой этикет в контексте мировых культурных традиций.
- Речевые нарушения, связанные с нарушением аффективных звеньев речевой функциональной системы.
- § 3 Модель формирования финансово-кредитного потенциала инвестиционной деятельности региона