Глава 1 МОДЕЛИ ДЕШИФРОВКИ
Первый тип исследовательских моделей, который будет нами рассмотрен, можно условно назвать моделями лингвистической дешифровки, так как, помимо своей основной теоретической функции (обоснования лингвистических понятий и утверждений), они в принципе могут иметь и некоторую прикладную — де- шифровочную — функцию.
Как мы помним, исходной информацией для моделей этого типа является текст, о котором заранее ничего не известно. Неизвестны ни язык (код), использованный для «шифровки» текста, ни генетические связи этого языка с уже известными языками, ни переводы текста на известные языки, ни та область действительности, которая описывается текстом. Для наглядности можно представить, что к нам в руки попал текст на марсианском языке, описывающий незнакомую нам марсианскую действительность и не имеющий никаких связей с текстами на известных нам языках. Помимо самого текста, мы имеем право использовать для его дешифровки только наше умение отличать черные точки от белых (этому легко «научить» и электронную вычислительную машину). Все остальные сведения, т. е. сведения об элементарных единицах текста (буквах или звуках, морфемах, словах, предложениях и, наконец, смыслах), классах элементарных единиц (гласных и согласных, лексических и грамматических морфемах, частях речи, типах предложений, семантических полях) и законах сочетания единиц различных классов (например, синтаксических связях слов в предложении), должны быть совершенно автоматически получены из текста.Можно представить себе последовательность алгоритмов, в которой каждый алгоритм выполняет одну из названных выше задач. Входной информацией для первого алгоритма являются текст и сведения о черных и белых точках (умение отличить черное от белого), а на выходе он вырабатывает информацию об алфавите символов (например, букв), с помощью которого этот текст записан. Каждый последующий алгоритм, решая ту или иную задачу, получает на вход информацию, выработанную предыдущим алгоритмом.
В частности, второй алгоритм находит в алфавите символов, который был обнаружен первым алгоритмом, гласные и согласные, подклассы внутри гласных и согласных и т. д., пока не будет установлено чтение всех букв. Последующие алгоритмы, пользуясь этой информацией, находят слоги, а затем морфемы, слова, классы морфем и классы слов. Когда найдены классы слов, можно приступить к решению синтаксических задач, в частности установить границы предложений и обнаружить связи слов в предложении. Наконец, когда открыты все существенные черты грамматики, можно переходить к поиску смысла слов и предложений. Результатом работы алгоритмов должно быть такое представление о языке, которое достаточно для того, чтобы перевести изученные таким образом тексты на какой-либо уже известный язык или сопоставить текстам изображенный в них кусок действительности.Если эта программа, впервые научно поставленная в пионерских работах Б. В. Сухотина , , окажется реализуемой, то основные лингвистические понятия будут сведены к весьма простым понятиям черных и
белых точек, ряду содержательных гипотез и описывающим их математическим функциям. Даже если она нереализуема, интересно выяснить, до какого уровня такого рода описание может быть успешно доведено.
Ниже мы излагаем наиболее простые алгоритмы Б. В. Сухотина, 3. Харриса и ряда других исследователей, которые можно отнести к числу дешифровочныхг. Укажем некоторые общие черты всех этих алгоритмов. Во-первых, в основе всех алгоритмов лежат простые и общие представления о языке, подтверждающиеся определенными универсальными закономерностями, например: «буква есть устойчивое сочетание точек»; «морфема есть устойчивое сочетание фонем»; «словоформа есть устой- чиеоє сочетание морфем»; «в каждом естественном языке имеется минимум два уровня — уровень значащих единиц (морфем, словоформ, конструкций) и уровень незначащих единиц (фонем)»; «в любом языке имеются лексические морфемы, причем распределение лексических морфем в тексте отличается от распределения грамматических морфем»; «синтаксическим различиям соответствуют семантические различия»; «слова, близкие по смыслу, стоят в тексте недалеко друг от друга» и т.
п. Во-вторых, во всех алгоритмах такого рода используется информация о дистрибуции элементов и их числовых параметрах2. В-третьих, задача обычно решается следующим образом. Сначала определяется множество д о- пустимых решений, а затем в этом множестве с помощью так называемых функций выгодности находится наилучшее решение. Функциями выгодности называются числовые функции, которые в случае правильных (наилучших) решений принимают определенное (например, минимальное возможное или максимальное возможное) значение. Каждая функция выгодности формализует некоторую содержательную гипотезу о возможных свойствах искомого объекта. Впервые, правда, в очень нестрогой форме, функции выгодности были использованы1 К обсуждаемому здесь вопросу имеют отношение работы Н Д. Андреева будет больше числа, стоящего в клетке NnNa, так как,
если в предложении встречается прилагательное в именительном падеже, в нем почти обязательно должно быть и существительное в именительном падеже, в то время как наличие существительного в винительном падеже не требует существительного в именительном падеже, ср. Длинный состав медленно полз по равнине; Яркое солнце лениво подымалось над лесом и Прочитай эту книгу; Пшеницу побило градом; Его знобило.
Таблица 5 а b с d е
| 90 | 35 | 50 | 29 | ||
| 90 | 80 | 30 | 40 | ||
| 35 | 80 | 78 | 31 | ... | |
| 50 | 30 | 78 | 45 | ... | |
| 29 | 40 | 31 | 45 | ... | |
| ... | ... |
Итак, на первом этапе решается задача нахождения грамматики языка по текстовым данным: составленная нами таблица содержит, в вероятностной форме, все правила связи словоформ в предложении.
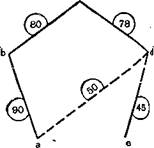
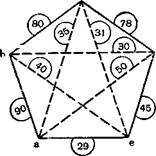
Имея эту вероятностную грамматику, мы возвращаемся, на втором этапе работы алгоритма, к первому предложению текста, составляем полный граф этого предложения (рис. 6) и над каждым ребром графа пишем цифру, взятую из соответствующей клетки таблицы (поскольку таблица симметрична относительно главной диагонали, безразлично, возьмем ли мы число из клетки XY или из клетки YX). Затем мы начинаем выкидывать из графа «лишние» ребра, начиная с того ребра, которому соответствует ми- а нимальное число. На каждом следующем Ьшаге снова выкидывается «минималь- с
ное» ребро, за исключением тех случаев, когда это делает граф несвязным. Ребра выкидываются до тех е пор, пока граф не превратится в дерево, которое и является искомым. Проил- люстр и ру ем п ри и ци~ пы работы алгоритма на следующем условном примере (табл. 5 и рис. 7).
Сначала, по первому основному условию, мы выкидываем ребро ае, являющееся «минимальным» (29), а затем, по тому же правилу, ребра bd (30), се (31), ас (35), be (40)
в указанной здесь последовательности. На следующем шаге (рис. 7, 2) необходимо выкинуть ребро ad (50), а не de (45), хотя 50 больше 45, так как удаление ребра de изолирует вершину е и делает граф несвязным. Ребра, нарисованные сплошной линией, и образуют искомое дерево предложения (см. рис. 7,2)
Аналогичным образом устанавливается дерево синтаксических связей для всех предложений данного текста, и работа алгоритма заканчивается.
Информация о непосредственных синтаксических связях словоформ, при условии что уже проведен морфологический анализ текста, позволяет получить весьма значительную информацию о лексическом аспекте языка и углубить наше понимание его синтаксиса. И. А. Мельчук, например, указал для этих условий способ выделения так
1 2
Рис. 7.
называемых устойчивых словосочетаний